
티스토리 뷰
[데이터사이언스/R] Red Wine Quality -아다부스팅 앙상블 ( AdaBoosting Ensemble)
ellie.strong 2021. 7. 14. 00:46<목차>
Red Wine Quality - 데이터 설명 및 분석
[데이터사이언스/R] 데이터 분석해보기 6 - Red Wine Quality
<목차> 1. 데이터 확인 1-1. 데이터 소개 - 레드 와인의 물리 화학적 특징과 퀄리티 점수를 보여주는 CSV파일 데이터 1-2. 데이터 구조 분석 - 데이터를 불러온다. wine - 데이터의 structure를 확인한다. s
programmer-ririhan.tistory.com
1. AdaBoosting Ensemble 모델 적용
- 첫번째 train, test set에 대하여 AdaBoosting Ensemble 모델을 적용한다.
library(ada)# train data로 모델 생성
gdis<-ada(rating~.-quality, data=train[[1]], iter=20, nu=1, type="discrete")
# test data로 rating 변수를 기준으로 예측
gdis<-addtest(gdis, subset(test[[1]], select=-c(quality, rating)), test[[1]]$rating)gdis
Call:
ada(rating ~ . - quality, data = train[[1]], iter = 20, nu = 1,
type = "discrete")
Loss: exponential Method: discrete Iteration: 20
Final Confusion Matrix for Data:
Final Prediction
True value 0 1
0 961 6
1 11 141
Train Error: 0.015
Out-Of-Bag Error: 0.047 iteration= 20
Additional Estimates of number of iterations:
train.err1 train.kap1 test.errs2 test.kaps2
20 20 15 15
- 예측 결과를 살펴본다.
summary(gdis)
Call:
ada(rating ~ . - quality, data = train[[1]], iter = 20, nu = 1,
type = "discrete")
Loss: exponential Method: discrete Iteration: 20
Training Results
Accuracy: 0.985 Kappa: 0.934
Testing Results
Accuracy: 0.9 Kappa: 0.523-> 정확도가 90%로 지금까지 사용했던 모든 모델의 정확도와 비교해 제일 높다.
2. 결과 시각화
2-1. 분류 오류 / 카파계수
- plot 함수로 예측 결과를 시각화해본다.
- plot 함수는 분류 오류(Error)와 일치도를 나타내는 카파계수(Kappa)를 그려준다.
- 옵션 TRUE, TRUE를 주어 train, test data 모두에 대해 그려준다.
plot(gdis, TRUE, TRUE)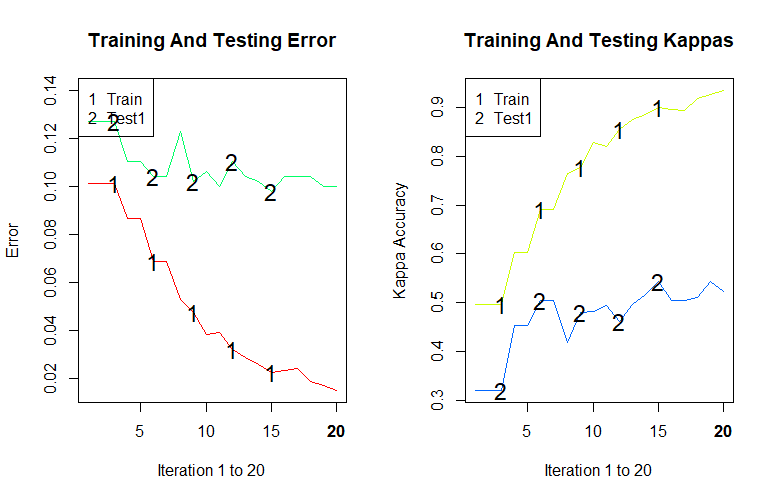
2-2. 변수의 중요성
- varplot 함수로 변수의 중요성을 시각화해본다.
varplot(gdis)
-> volatile.acidity 변수가 분류에 가장 중요한 변수로 사용되었음을 알 수 있다.
2-3. 중요 변수에 대한 산점도
- pairs 함수로 중요변수에 대한 산점도를 그려본다.
- maxvar 옶션을 통해 변수의 수를 지정할 수 있다.
-> 중요도가 높은 변수가 우선적으로 선택 된다.
pairs(gdis, subset(train[[1]], select=-c(quality, rating)), maxvar=3)
pairs(gdis, subset(test[[1]], select=-c(quality, rating)), maxvar=3)

ref.
- R, SAS, MS-SQL을 활용한 데이터마이닝, 이정진
- R로 배우는 데이터분석 #20 - 앙상블 모형 : 네이버 포스트 (naver.com)