
티스토리 뷰
모락 프로젝트를 진행하는 과정에서의 트러블 슈팅 내용을 다루고 있습니다.
오늘은 byte[]를 String으로 변환하는 방법에 대해 이야기해보려 합니다.
먼저 QA 과정에서 발견된 문제 상황에 대해 공유해드리려고해요.
저희는 로직 상 처리하지 못한 예외에 대해서는 문제 상황을 재현해 볼 수 있도록 요청 정보를 모두 로깅하고 있었습니다. 그런데 로그 파일을 까고 보니 요청 바디(Request Body)가 다음과 같이 이상한 숫자들로 출력되고 있었습니다. 분명 PR을 날리기 전에 요청 바디가 잘 찍히는 것을 확인했었는데.. 이상한 일이었습니다🥲
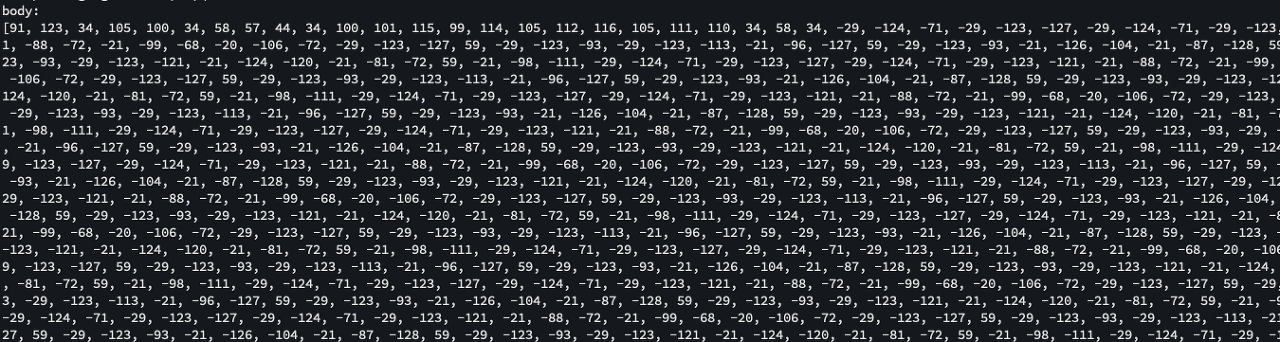
이와 관련해 왜 이러한 문제가 발생했는지, 어떻게 해결했는지 이야기해보겠습니다.
new String()을 사용했던 이유
private static StringBuilder getBody(ContentCachingRequestWrapper requestWrapper) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("body: ").append(NEWLINE);
stringBuilder.append(new String(requestWrapper.getContentAsByteArray()));
return stringBuilder;
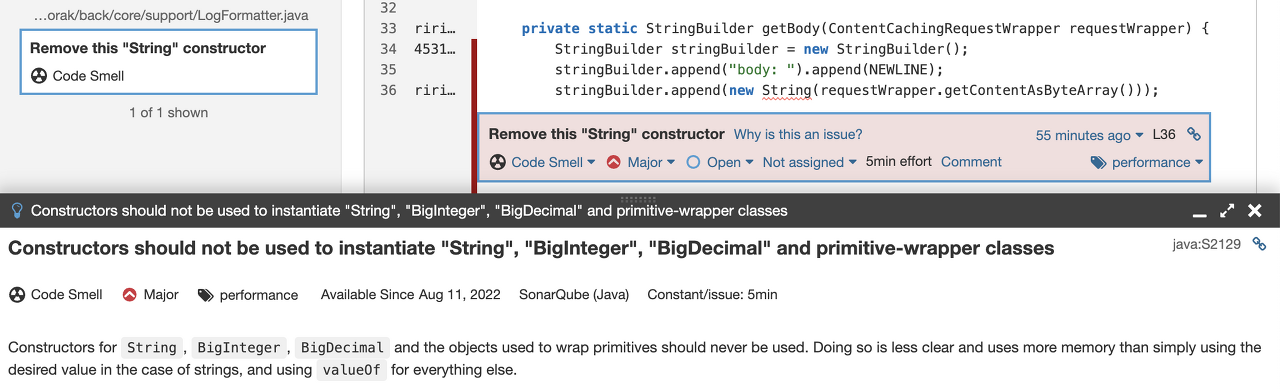
}저희는 ContentCashingRequestWrapper#getContentAsByteArray()를 사용해 요청 바디를 byte[]로 불러와 사용하기 때문에 byte[]를 String으로 변환해야했습니다. 검색 결과 byte[]를 String으로 변환하기 위해서는 String의 생성자를 이용해 직접 String으로 만들어주면 된다는 글이 많았습니다.

어렴풋한 기억에 Java에서는 String과 Wrapper 클래스에 대해 객체 풀(Object Pool)을 이용하기 때문에 생성자를 사용하지 말고, valueOf()를 사용하는 것이 좋다고 했던 것 같아 valueOf()를 사용해보려 했지만 byte[]에 대한 valueOf()는 제공되고 있지 않아 String의 생성자를 직접 사용했었습니다.
Arrays.toString()은 내가 생각한 녀석이 아니었다.
요청 바디가 잘 출력되는 것을 확인하고 PR을 날렸습니다. 하지만 제 PR의 코드를 정적 분석한 소나큐브가 제 코드에서 냄새가 난다고 하더라구요ㅠㅅㅠ 당시 이 냄새를 없애야 한다는 생각에 이래저래 코드를 바꿔보다가 Arrays.toString()을 발견하고 혼자 좋다면서 테스트도 안 해보고 PR에 커밋을 붙였습니다. 메서드 이름이 누가봐도 배열을 String으로 출력해준다는 것 같지 않나요?😅
Arrays.toString(requestWrapper.getContentAsByteArray());이 메서드 때문에 요청 바디가 다음과 같이 찍히는 버그를 만나게 된것이었습니다.
Arrays.toString()의 구현 로직을 보니 단순히 배열의 모든 byte를 출력할 때 사용하는 메서드였습니다.
public static String toString(byte[] a) {
if (a == null)
return "null";
int iMax = a.length - 1;
if (iMax == -1)
return "[]";
StringBuilder b = new StringBuilder();
b.append('[');
for (int i = 0; ; i++) {
b.append(a[i]);
if (i == iMax)
return b.append(']').toString();
b.append(", ");
}
}
new String()의 charset 파라미터
그래서 다시 String의 생성자를 사용하는 방식으로 회귀했습니다. 이와 관련해서 팀원 차리가 charset 파라미터도 넣어주면 좋을 것 같다는 조언을 해주었습니다.
private static StringBuilder getBody(ContentCachingRequestWrapper requestWrapper) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("body: ").append(NEWLINE);
stringBuilder.append(new String(requestWrapper.getContentAsByteArray(), StandardCharsets.UTF_8));
return stringBuilder;
}우리는 charset 파라미터를 통해 String으로 변환하려는 byte[]의 byte가 어떠한 charset(UTF_8, US_ASCII, ISO_8859_1 등)인지 명시해줄 수 있습니다. 디코딩할 때 이를 활용하겠죠?😄

결과적으로 문자열 및 이모지 모두 디코딩이 잘 되었으며, 소나큐브에서도 이를 코드 스멜로 잡아내지 않았습니다.
new String()은 어떤 charset을 사용할까?
사실 그냥 new String()을 사용해도 문자열과 이모지 모두 디코딩이 잘 됩니다. 그래서 궁금해졌습니다. 그럼 new String()에서는 default charset으로 UTF_8을 사용하는건가?
docs를 살펴보면 using the platform's default charset, 즉 플랫폼의 기본 charset을 사용한다고 설명하고 있습니다.

관련해서 찾아보니 플랫폼은 JVM을 말한다고 합니다.
Every instance of the Java virtual machine has a default charset, which may or may not be one of the standard charsets. The default charset is determined during virtual-machine startup and typically depends upon the locale and charset being used by the underlying operating system. (출처: Oracle 공식 문서)
JVM의 default charset을 알려주는 Charset.defaultCharset()을 이용해 찍어보니 제 노트북에서는 UTF-8로 적용되어 있었습니다.
실습 환경
openjdk 11.0.11 2021-04-20 OpenJDK Runtime Environment AdoptOpenJDK-11.0.11+9 (build 11.0.11+9)
OpenJDK 64-Bit Server VM AdoptOpenJDK-11.0.11+9 (build 11.0.11+9, mixed mode)
System.out.println("Charset.defaultCharset() = " + Charset.defaultCharset());
결론
- String 생성자를 이용해 byte[]를 String으로 변환(디코딩)할 수 있습니다.
- new String(), new String(byte[], Charset) 둘 다 사용할 수 있지만 new String(byte[], Charset)이 “이 메서드는 디코딩을 하는 애에요”라고 명시적으로 말해주는 것 같아 new String(byte[], Charset)을 선택했습니다.
참고 자료
- https://tech.wheejuni.com/2018/05/21/java-string/
- https://stackoverflow.com/questions/14402794/object-pool-for-java-wrappers-and-string
'Backend > Java' 카테고리의 다른 글
| Spark Java에서 에러 메시지 전송하기 (0) | 2022.04.07 |
|---|---|
| DAO, DTO, Service, Controller (feat. 체스미션) (0) | 2022.04.06 |
| 처음 만난 SparkJava (0) | 2022.04.03 |
| 공유 중인 가변 데이터는 동기화해 사용하라 (0) | 2022.03.30 |
| Enum에서 상수를 사용하는 방법 (4) | 2022.03.17 |